
About me
I am a Research Scientist at Google DeepMind (GenAI), advancing the frontiers of large language models through novel architectures and efficient pretraining strategies. My work at Google has included extending model context length by over 30x, contributing to the Gemini Nano models, and enhancing YouTube search with state-of-the-art AI. More broadly, I am interested in in-context learning, long context, length generalization, and reasoning capabilities of LLMs.
I obtained my Ph.D. in Computer Science from the University of Southern California, where I was fortunate to be advised by Aram Galstyan and Greg Ver Steeg. My thesis was on information stored in neural network weights or activations, and its connections to generalization, memorization, stability and learning dynamics. Prior to USC, I received my M.S. and B.S. degrees in Applied Mathematics and Computer Science from Yerevan State University. When I’m not training models, I enjoy reading, cinema, playing pool, and exploring NYC.
Recent Highlights
- [Sept 2025] Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation accepted at NeurIPS 2025!
- [Summer 2025] Hosted interns M. Emrullah ILDIZ and Zhiweu Xu. Worked with another intern: Hanseul Cho. Expect exciting research on improved transformer architecture and in-context learning!
- [Summer 2024] Worked with 2 interns: Asher Trockman and Sangmin Bae.
- [Feb, 2023] Presented my work [slides] at Rising Stars in AI Symposium 2023 at KAUST in Saudi Arabia.
Publications and preprints
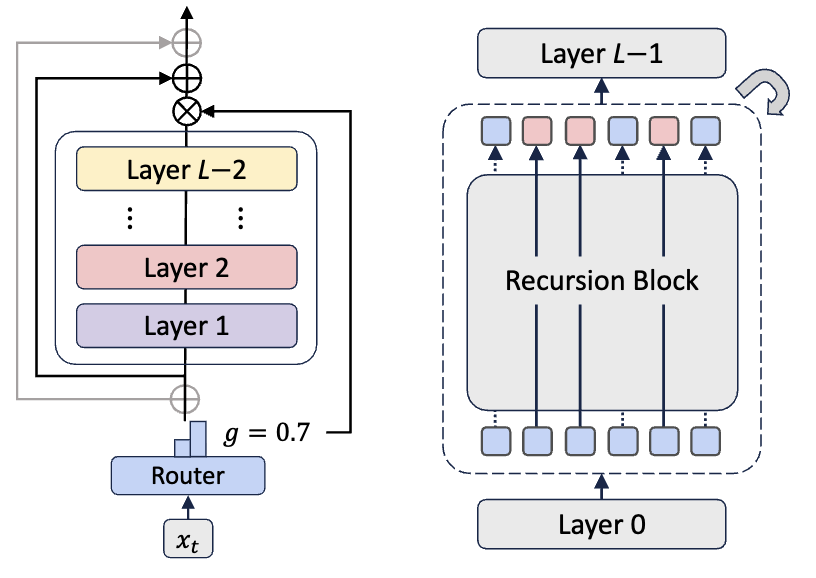
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
NeurIPS 2025, [paper, bibTeX]
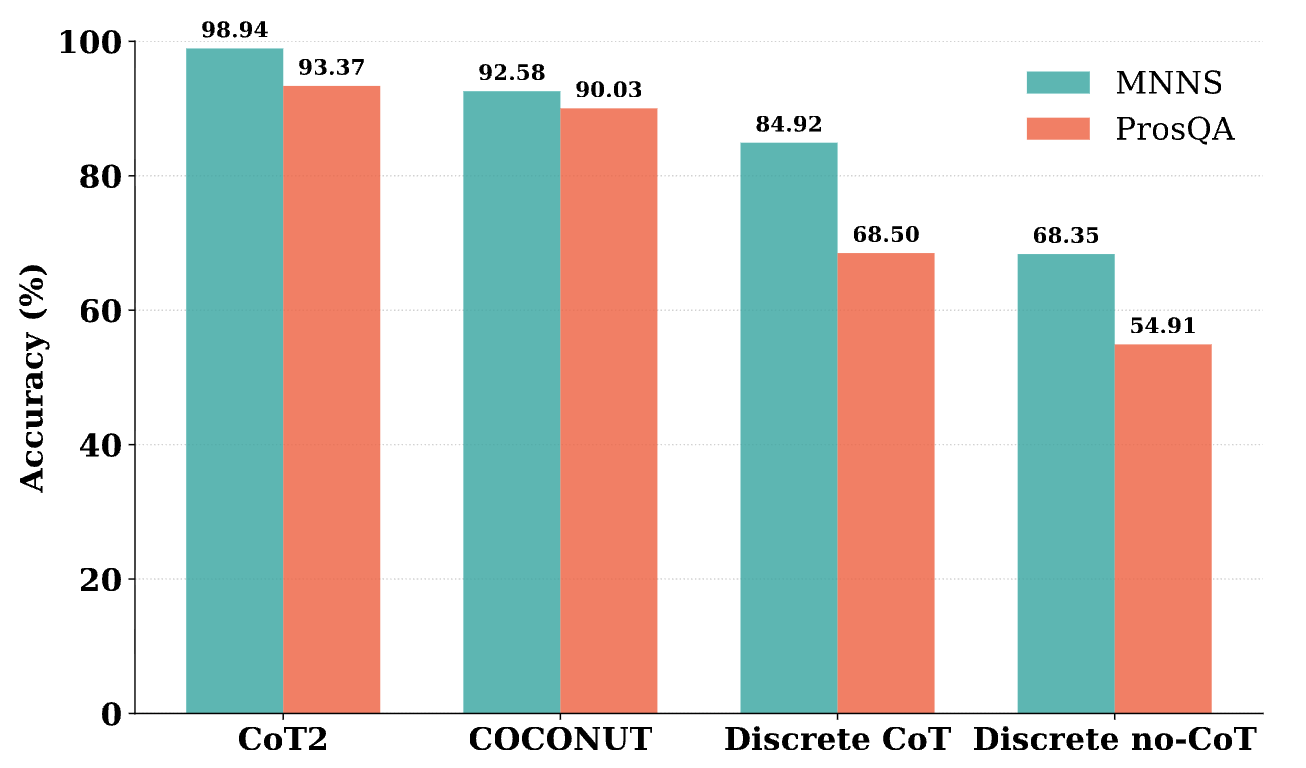
Continuous Chain of Thought Enables Parallel Exploration and Reasoning
ICML 2025 TokShop Workshop, [paper, bibTeX]
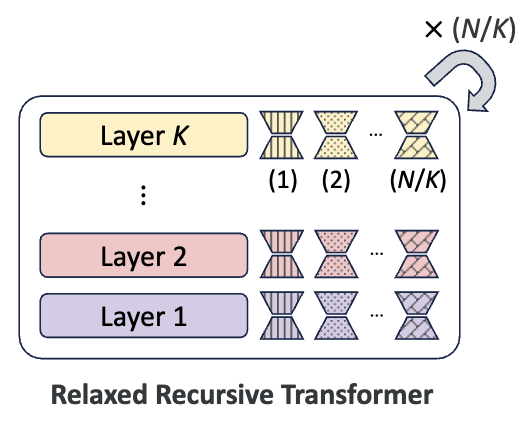
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
ICLR 2025, [paper, bibTeX]
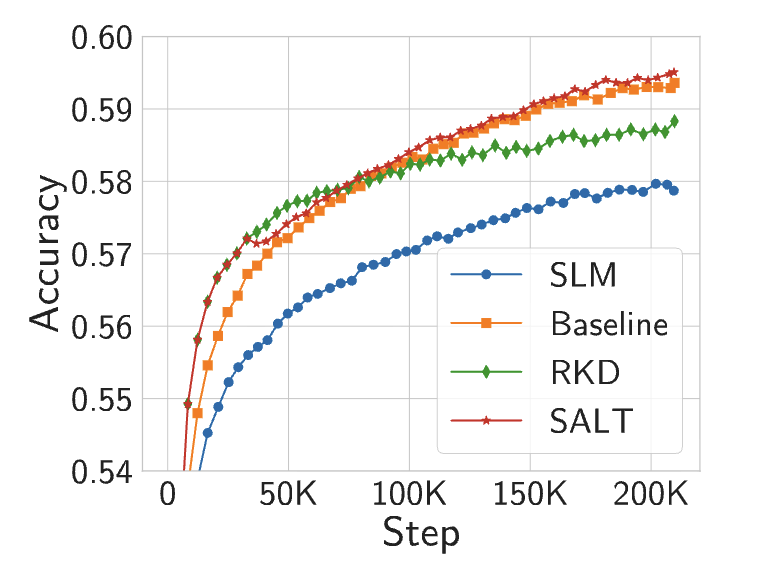
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
arXiv preprint, [paper, bibTeX]
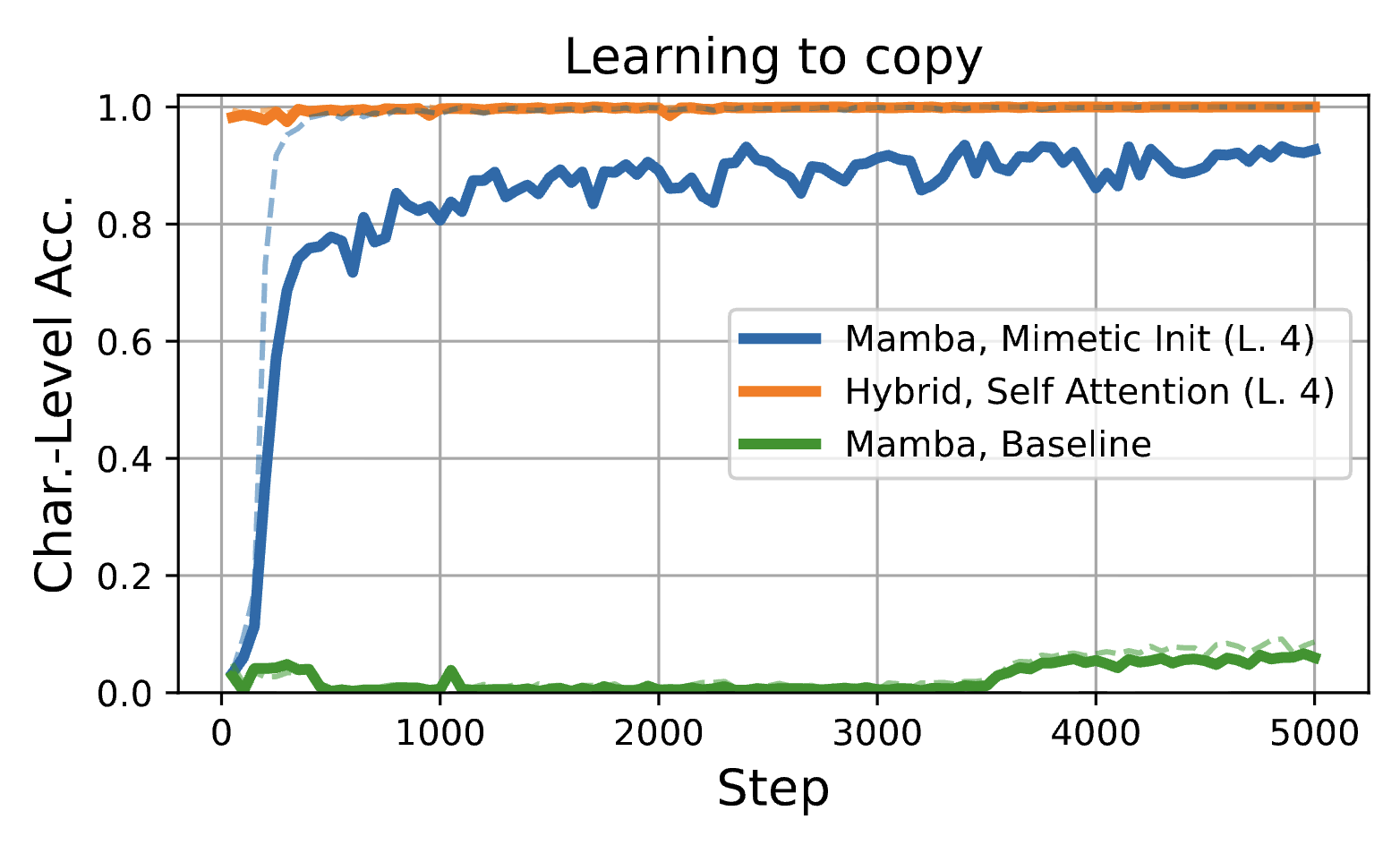
Mimetic Initialization Helps State Space Models Learn to Recall
ICLR 2025 Workshop Weight Space Learning, [paper, bibTeX]
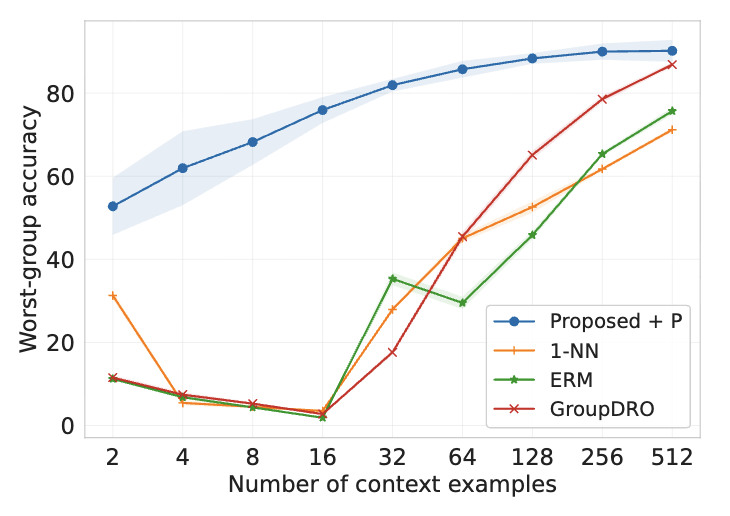
In-context Learning in Presence of Spurious Correlations
Under review at TMLR, [paper, bibTeX]
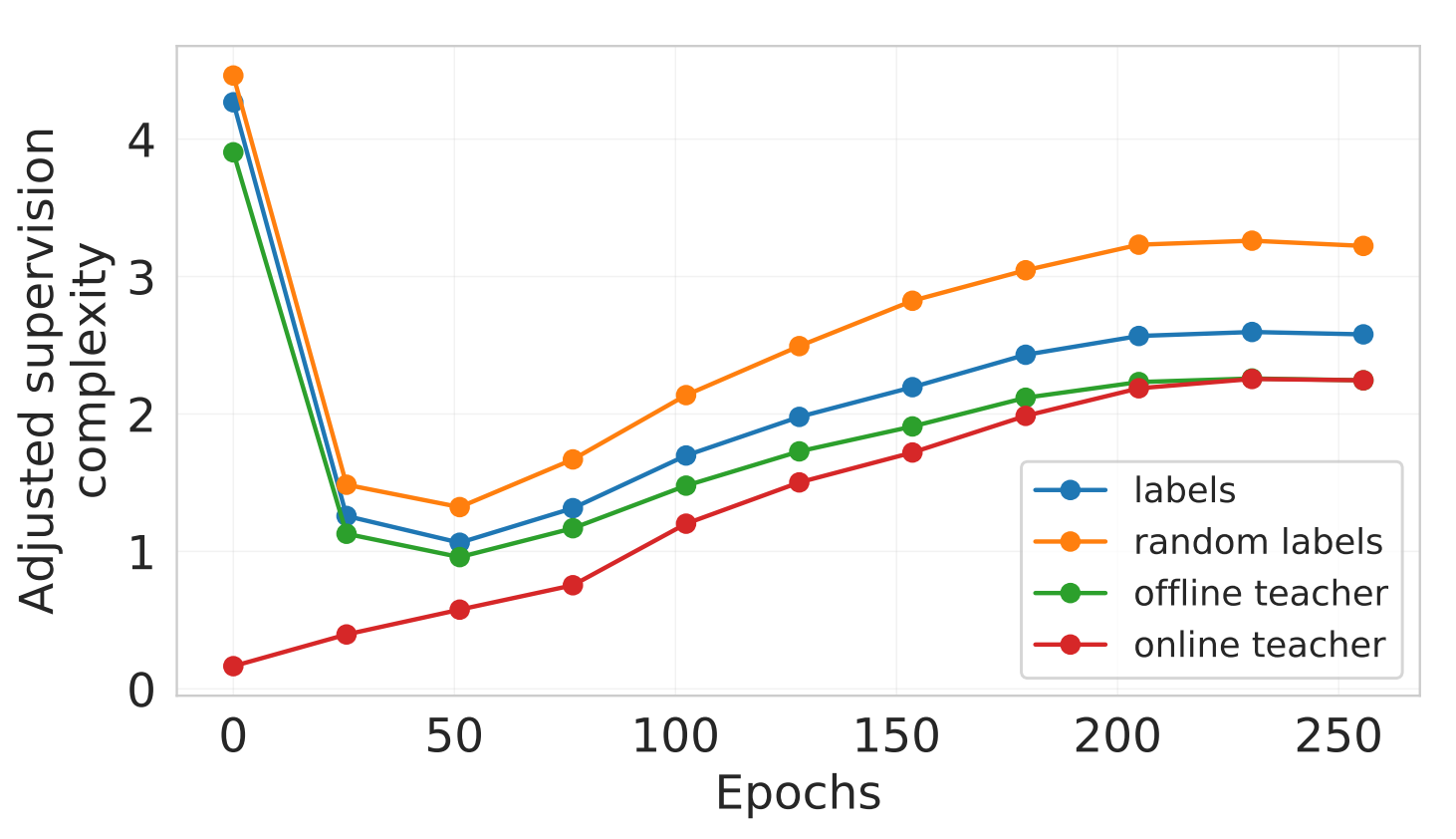
Supervision Complexity and its Role in Knowledge Distillation
ICLR 2023, [paper, bibTeX]
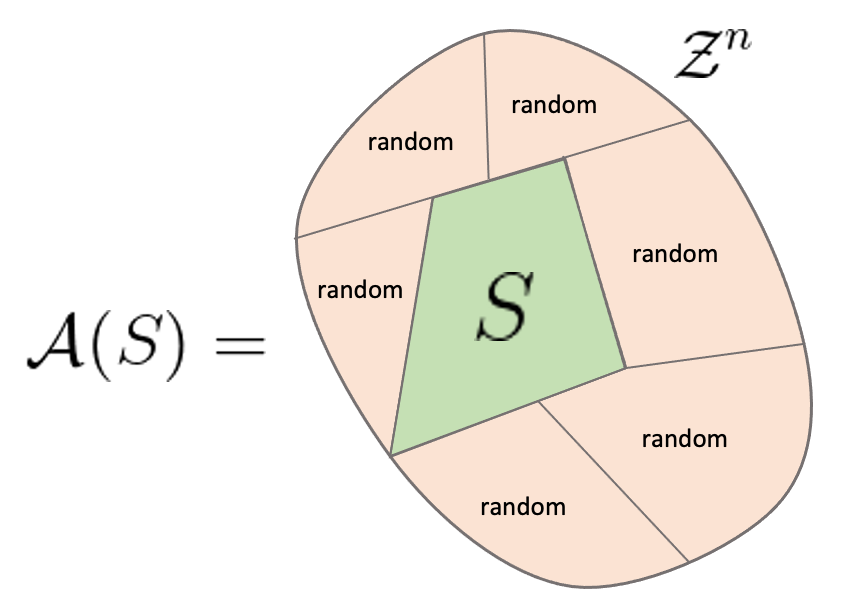
Formal limitations of sample-wise information-theoretic generalization bounds
IEEE Information Theory Workshop 2022 [arXiv, bibTeX]
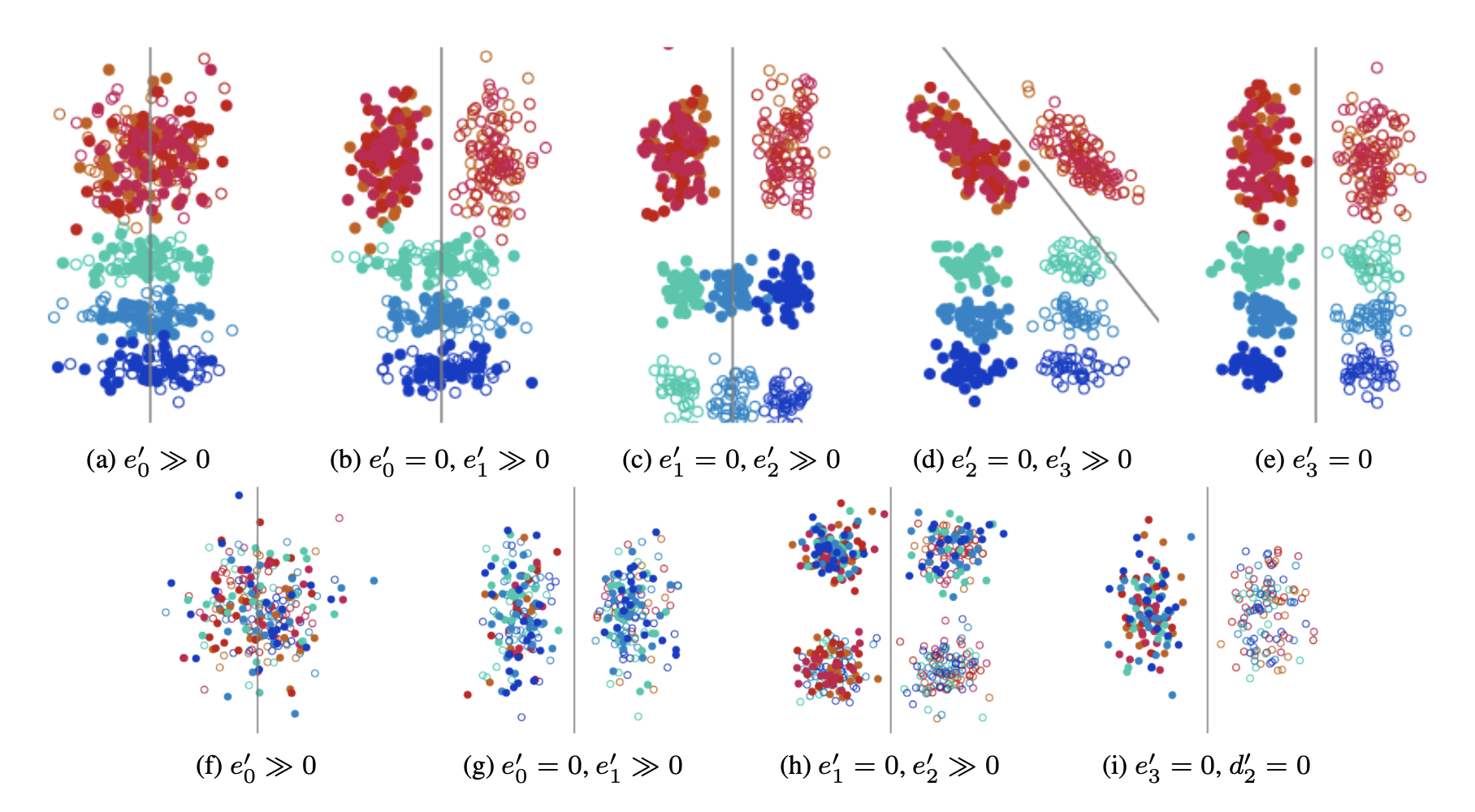
Failure Modes of Domain Generalization Algorithms
CVPR 2021 [arXiv, code 1 2, bibTeX]
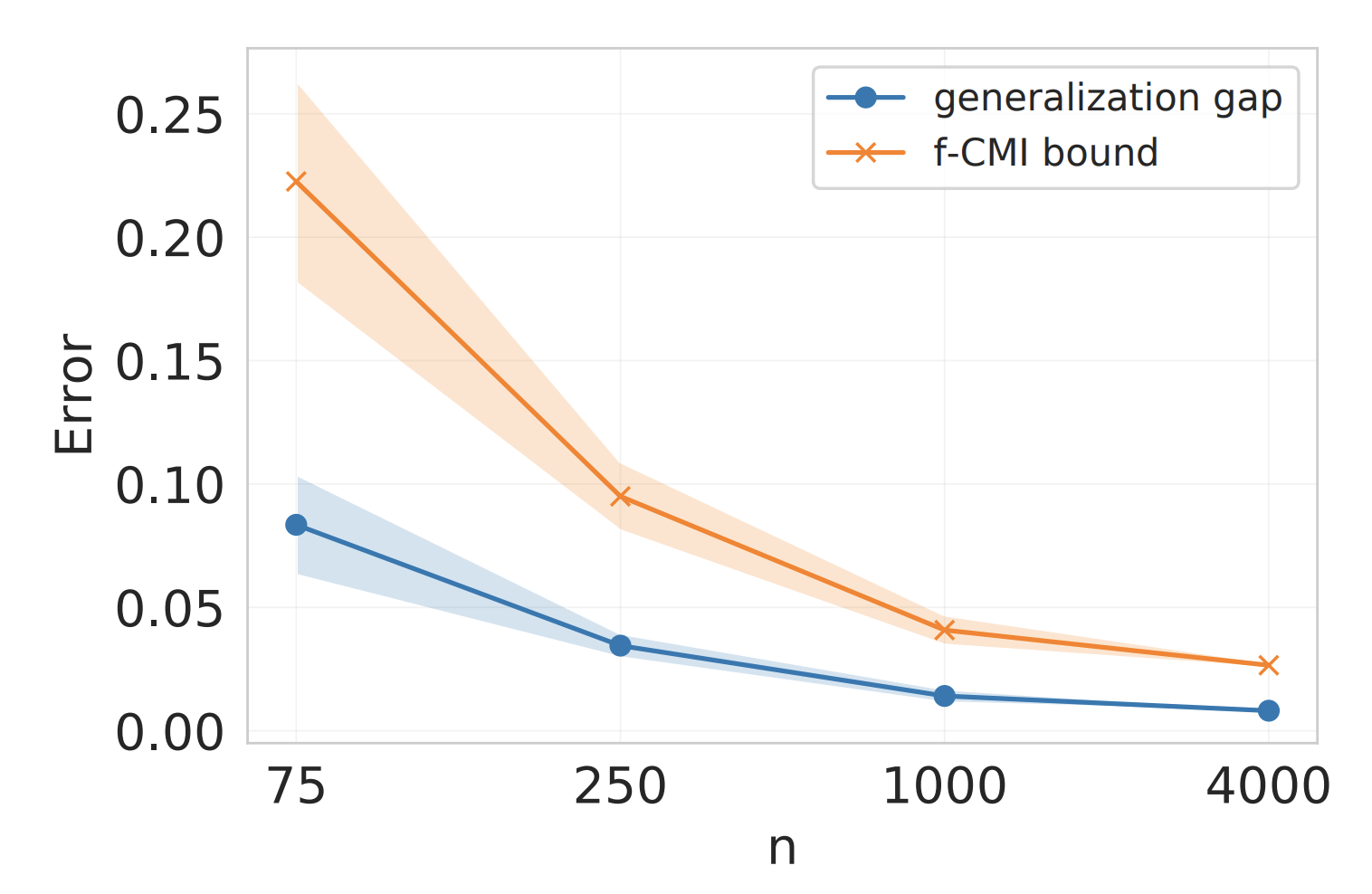
Information-theoretic generalization bounds for black-box learning algorithms
NeurIPS 2021 [arXiv, code, bibTeX]

Estimating informativeness of samples with smooth unique information
ICLR 2021 [arXiv, code, bibTeX]
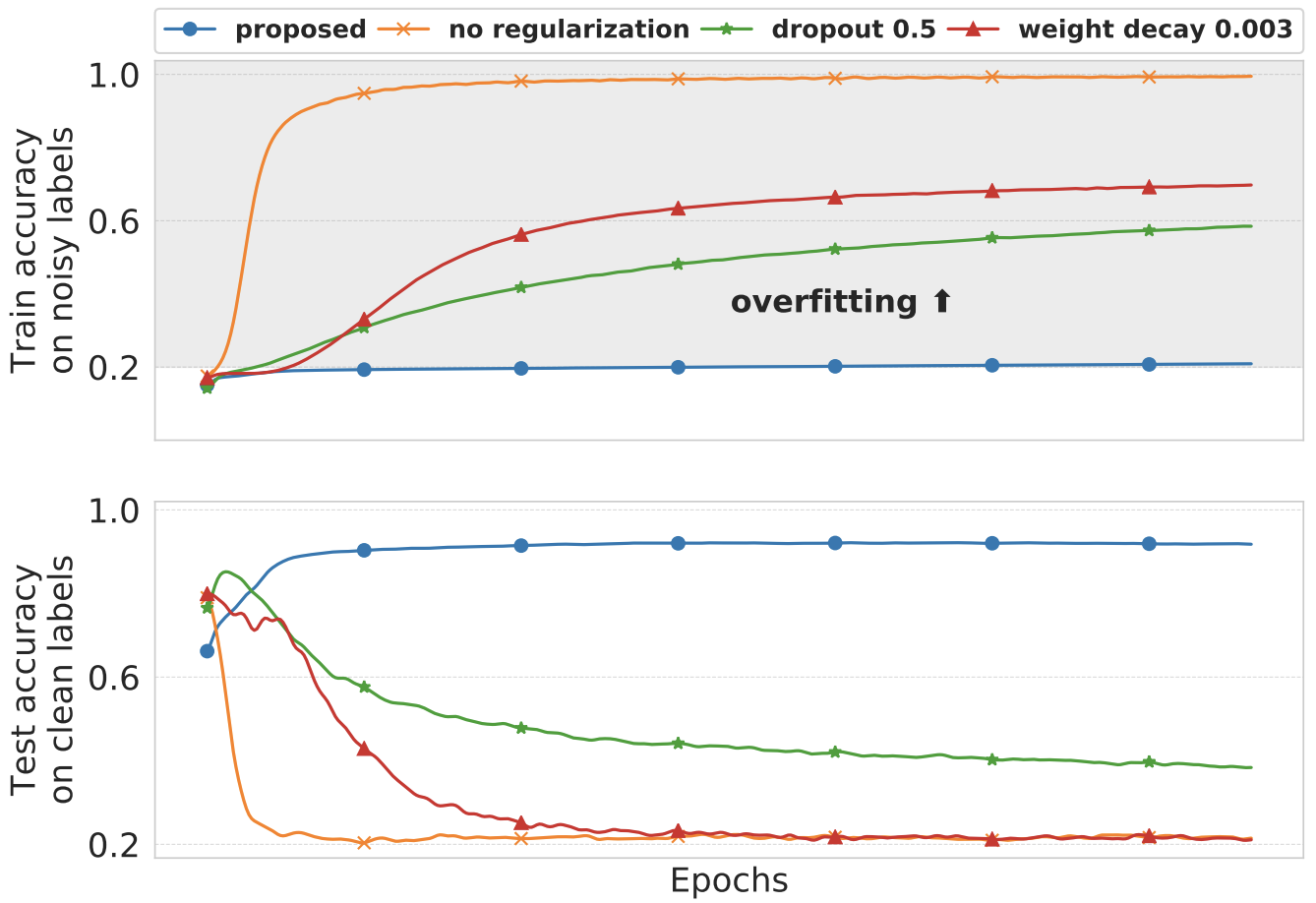
Improving generalization by controlling label-noise information in neural network weights
ICML 2020 [arXiv, code, bibTeX]
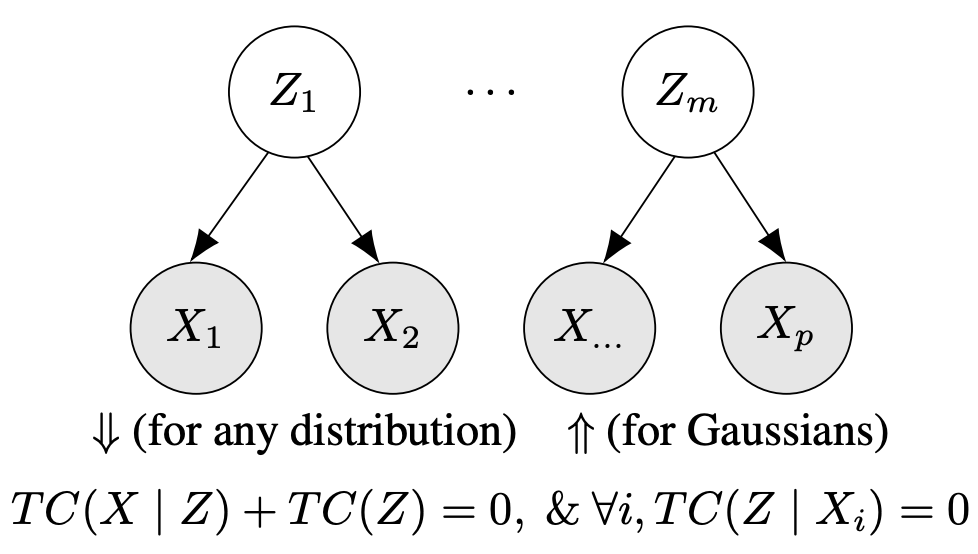
Fast structure learning with modular regularization
NeurIPS'19 [arXiv, code, bibTeX]
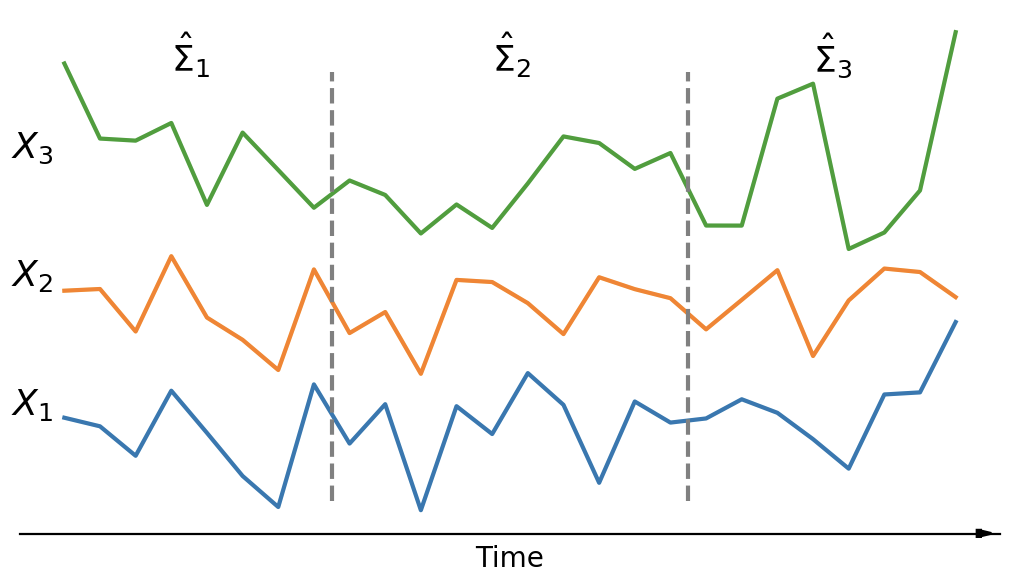
Efficient Covariance Estimation from Temporal Data
arXiv preprint [arXiv, code, bibTeX]
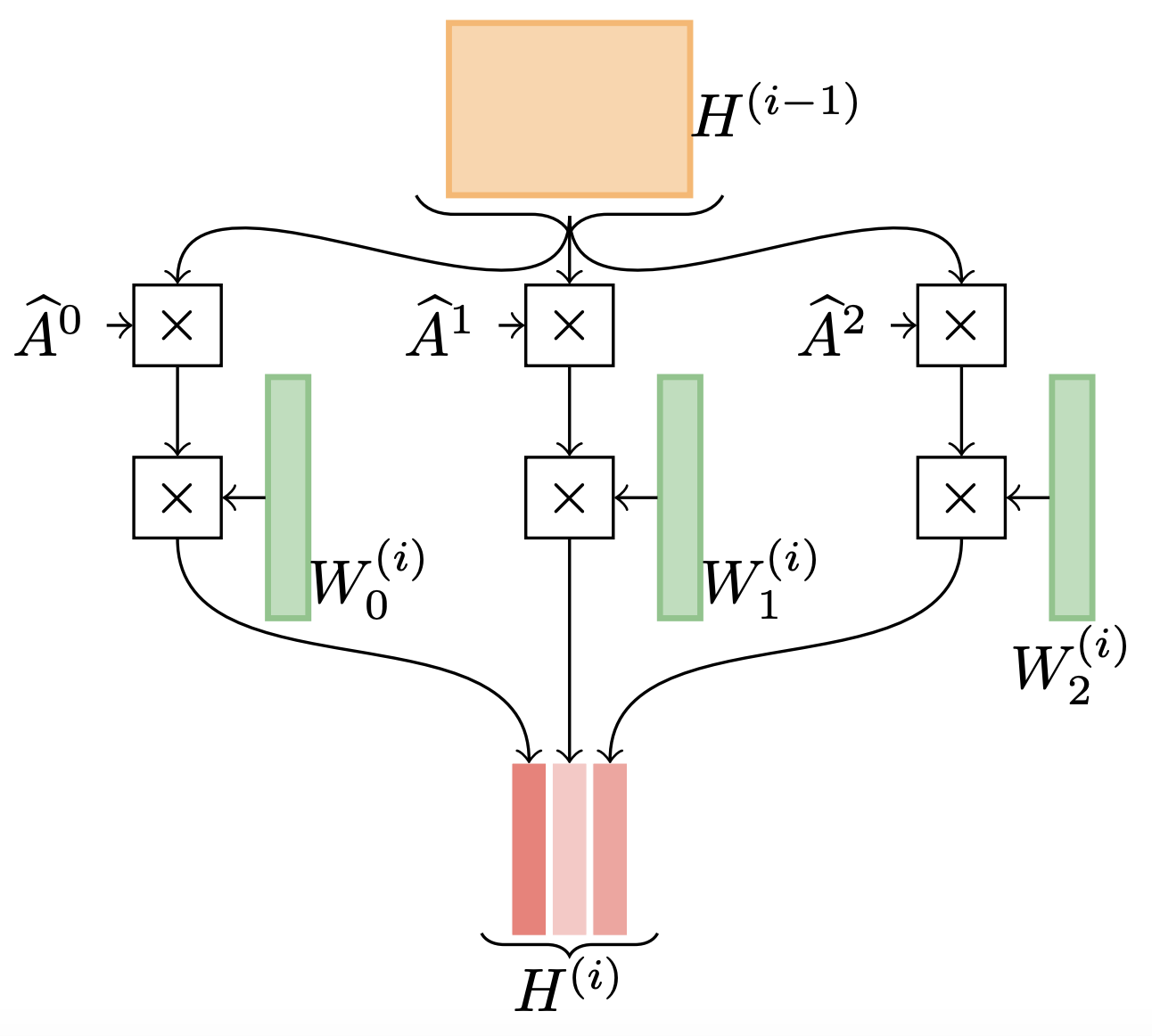
Mixhop: Higher-order graph convolution architectures via sparsified neighborhood mixing
ICML'19 [arXiv, code, bibTeX]
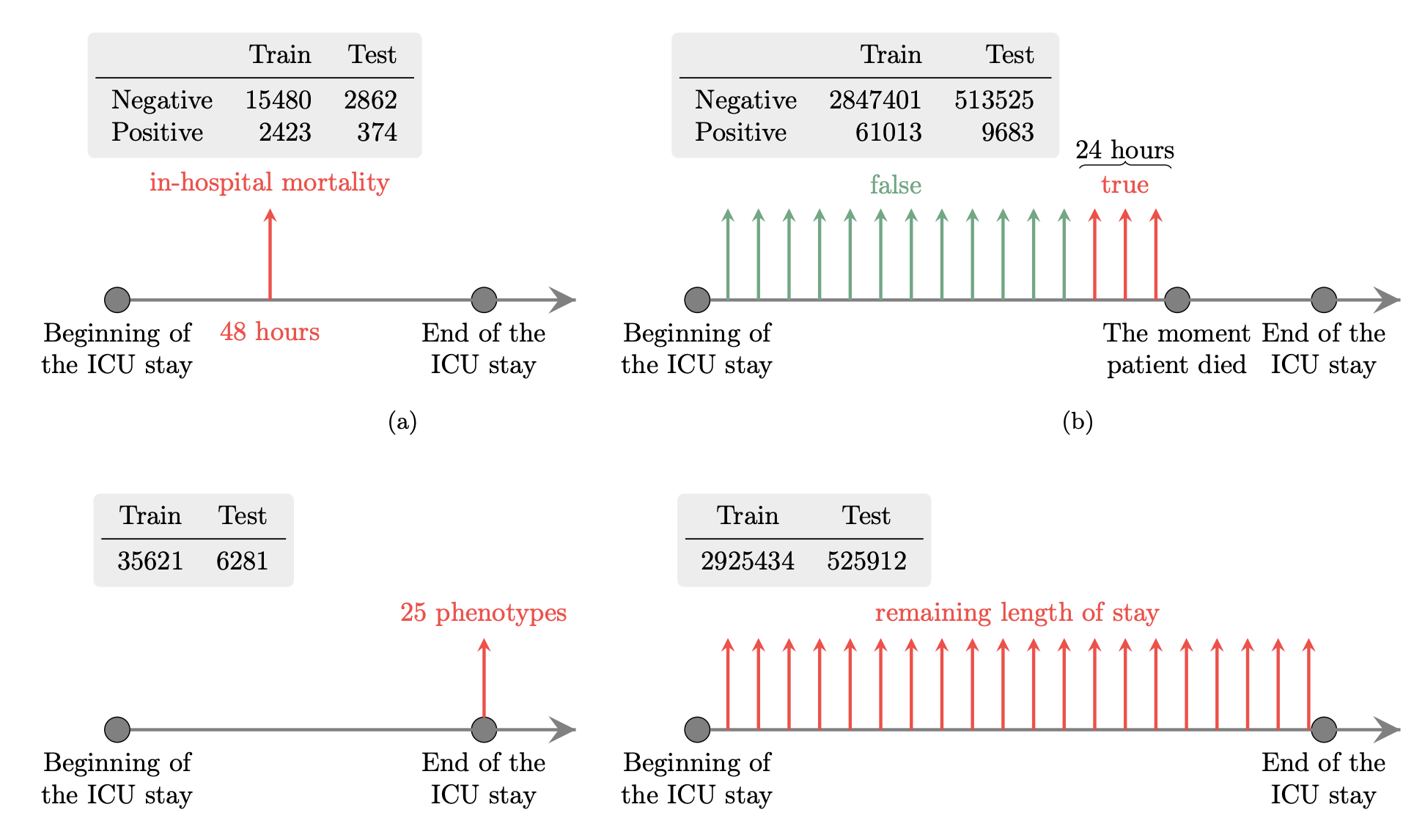
Multitask learning and benchmarking with clinical time series data
Nature, Scientific data 6 (1), 96 [arXiv, code, bibTeX]
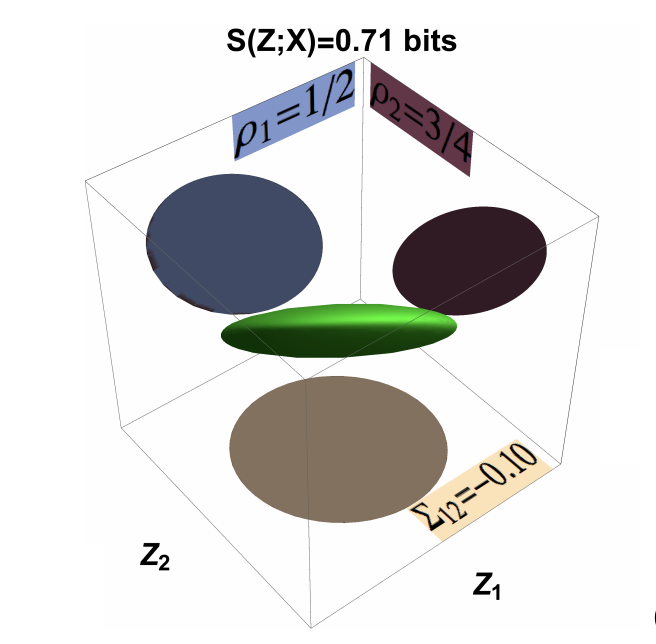
Disentangled representations via synergy minimization
Allerton'17 [arXiv, bibTeX]