I am a research scientist at Google Research, where I focus on developing efficient and capable language models, particularly relatively smaller ones (up to 10 billion parameters). My research explores designing novel architectures and knowledge distillation techniques to improve both the quality and efficiency of these models. I also work on developing techniques to extend the context length of language models by over 30 times. At Google, I also contribute to the improvement of Gemini Nano models and YouTube search with state-of-the-art AI techniques. More broadly, I am interested in novel self-supervised learning objectives, generalization phenomenon of deep neural networks, learning theory, in-context learning, and out-of-distribution generalization.
I obtained my Ph.D. in Computer Science from the University of Southern California, where I was fortunate to be advised by Aram Galstyan and Greg Ver Steeg. My thesis was on information stored in neural network weights or activations, and its connections to generalization, memorization, stability and learning dynamics. Prior to USC, I received my M.S. and B.S. degrees in Applied Mathematics and Computer Science from Yerevan State University. Outside of work, I am interested in reading, cinema, billiards, skiing, chess, music, and philosophy.
Updates
[July 17, 2023] Excited to share that I have joined Google Research NYC as a research scientist.
[June 16, 2023] I have graduated from USC with a PhD in Computer Science!
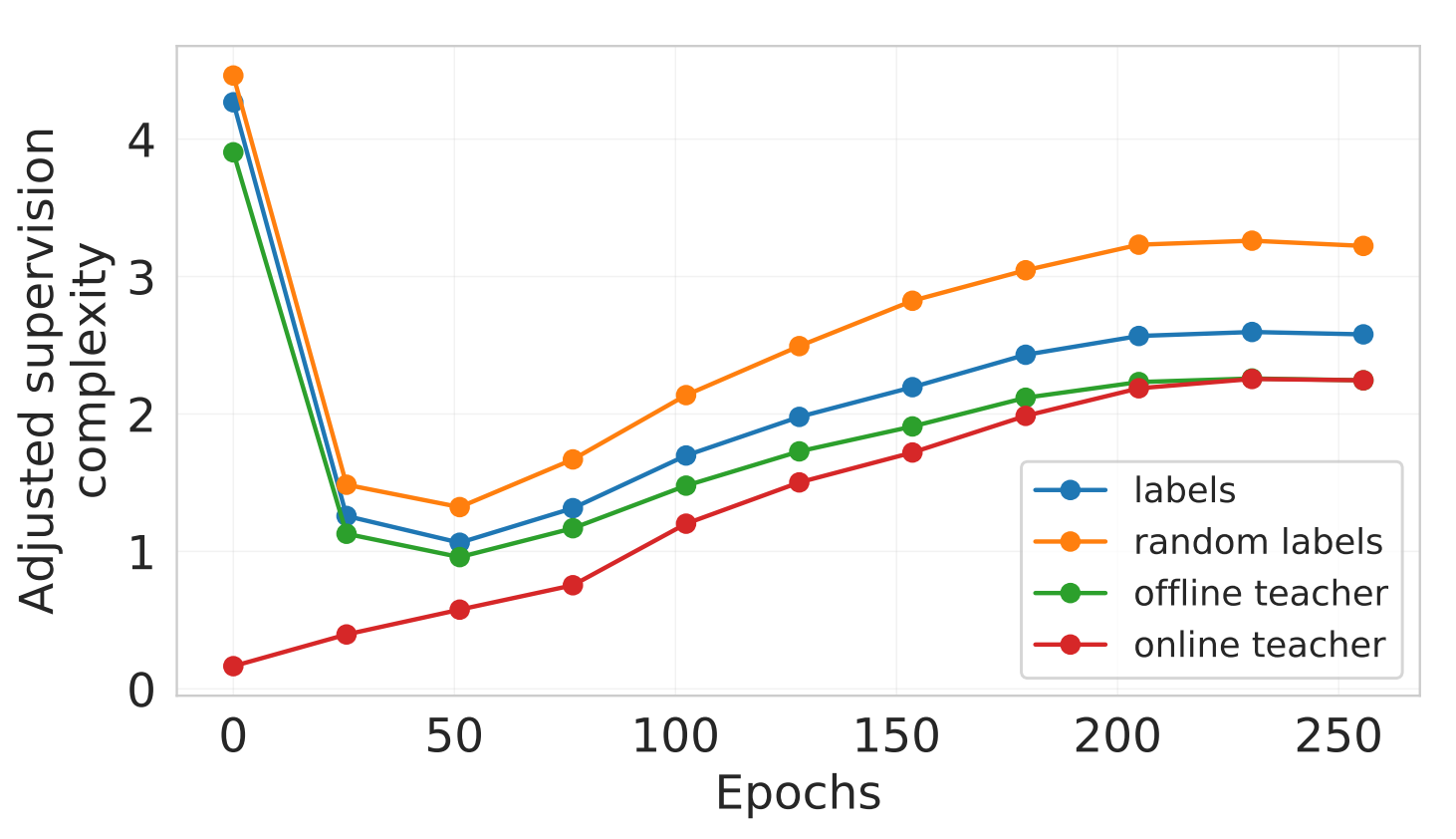
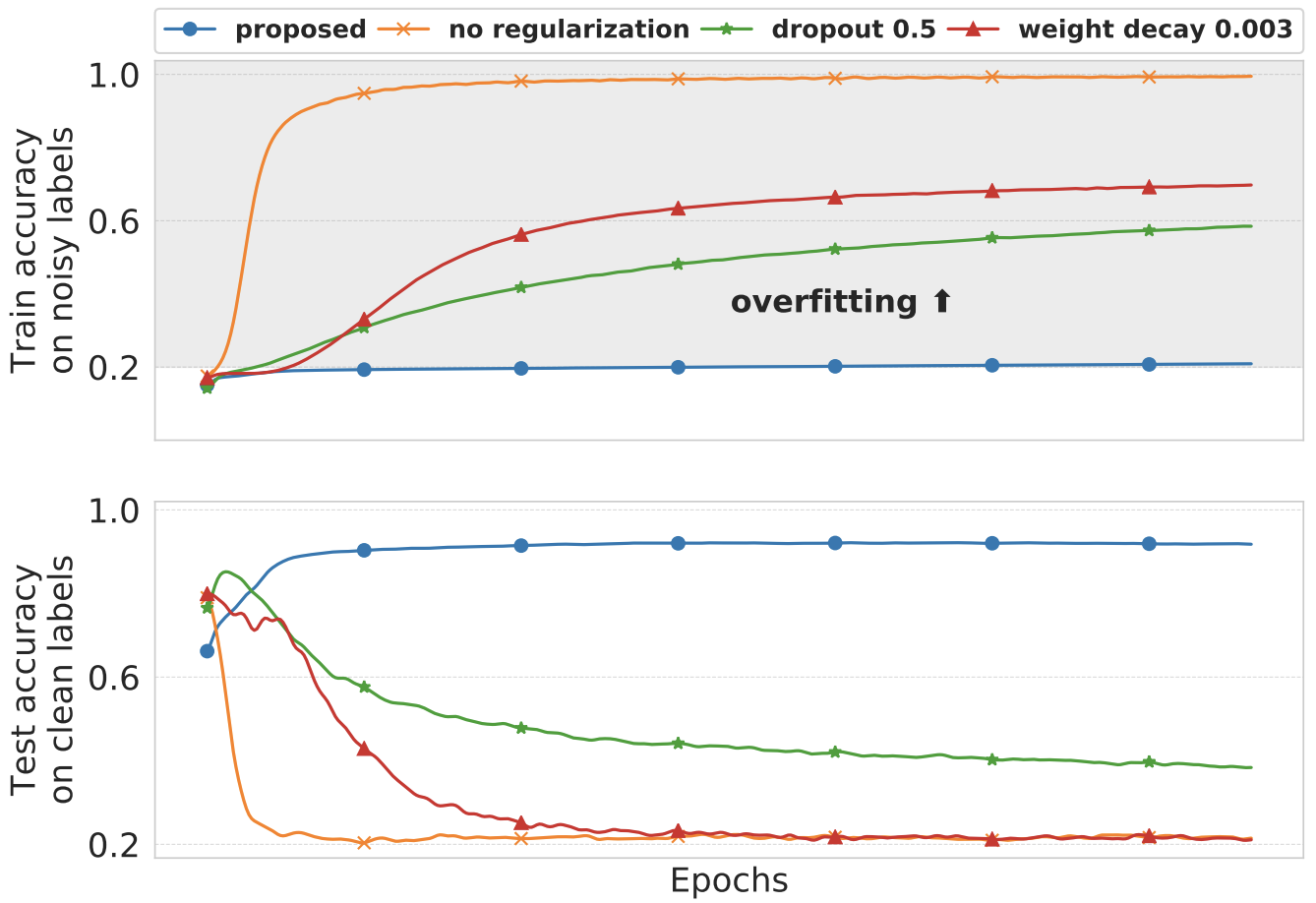
[Jan 21, 2023] Our work “Supervision Complexity and its Role in Knowledge Distillation” was accepted to ICLR 2023.
[Aug 3, 2022] Our work “Formal limitations of sample-wise information-theoretic generalization bounds” was accepted to the 2022 IEEE Information Theory Workshop conference.
[May 16, 2022] Started a summer internship at Google Research, New York. Will be working with Ankit Singh Rawat and Aditya Menon.
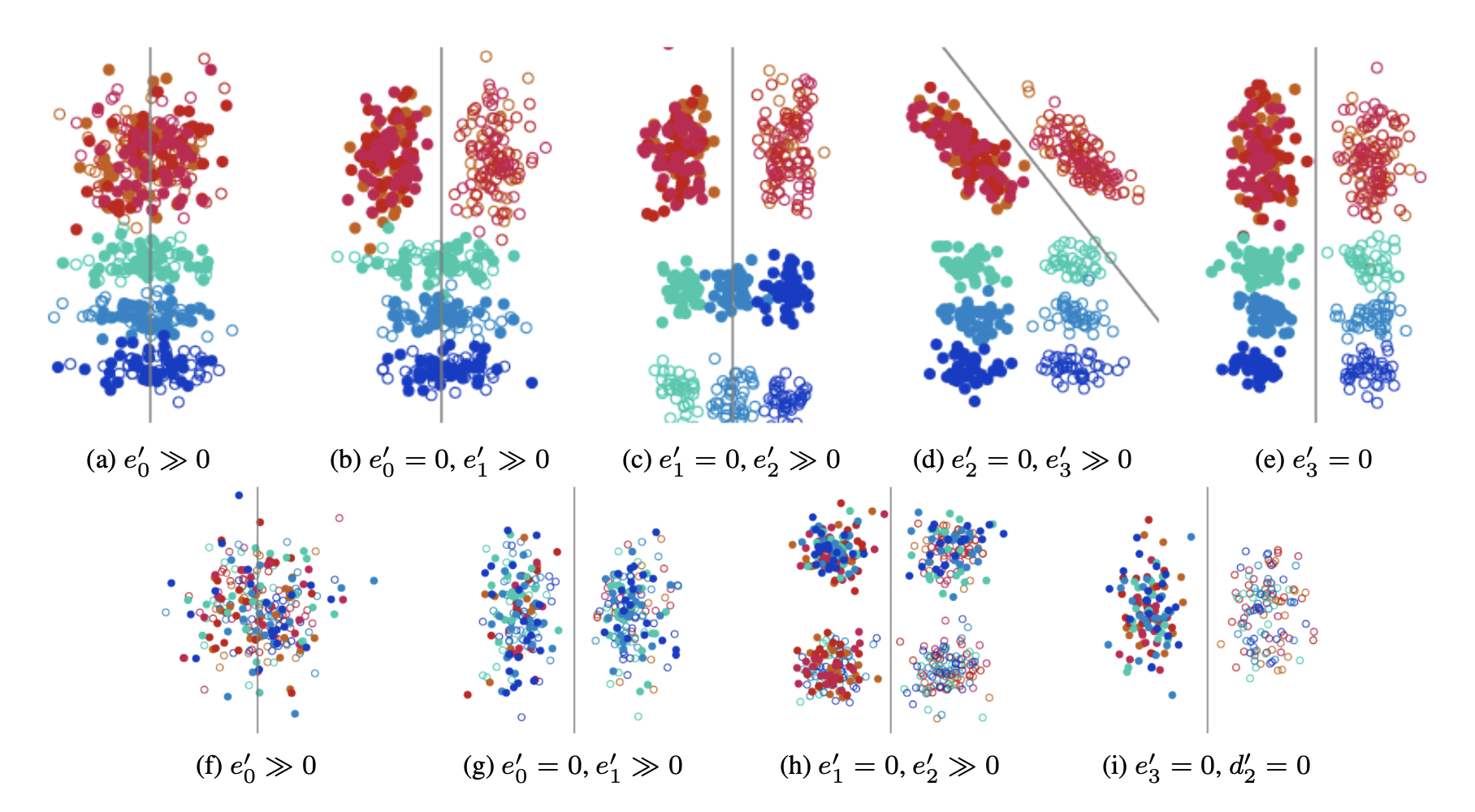
[March 2, 2022] Our work “Failure Modes of Domain Generalization Algorithms” was accepted to CVPR 2022.
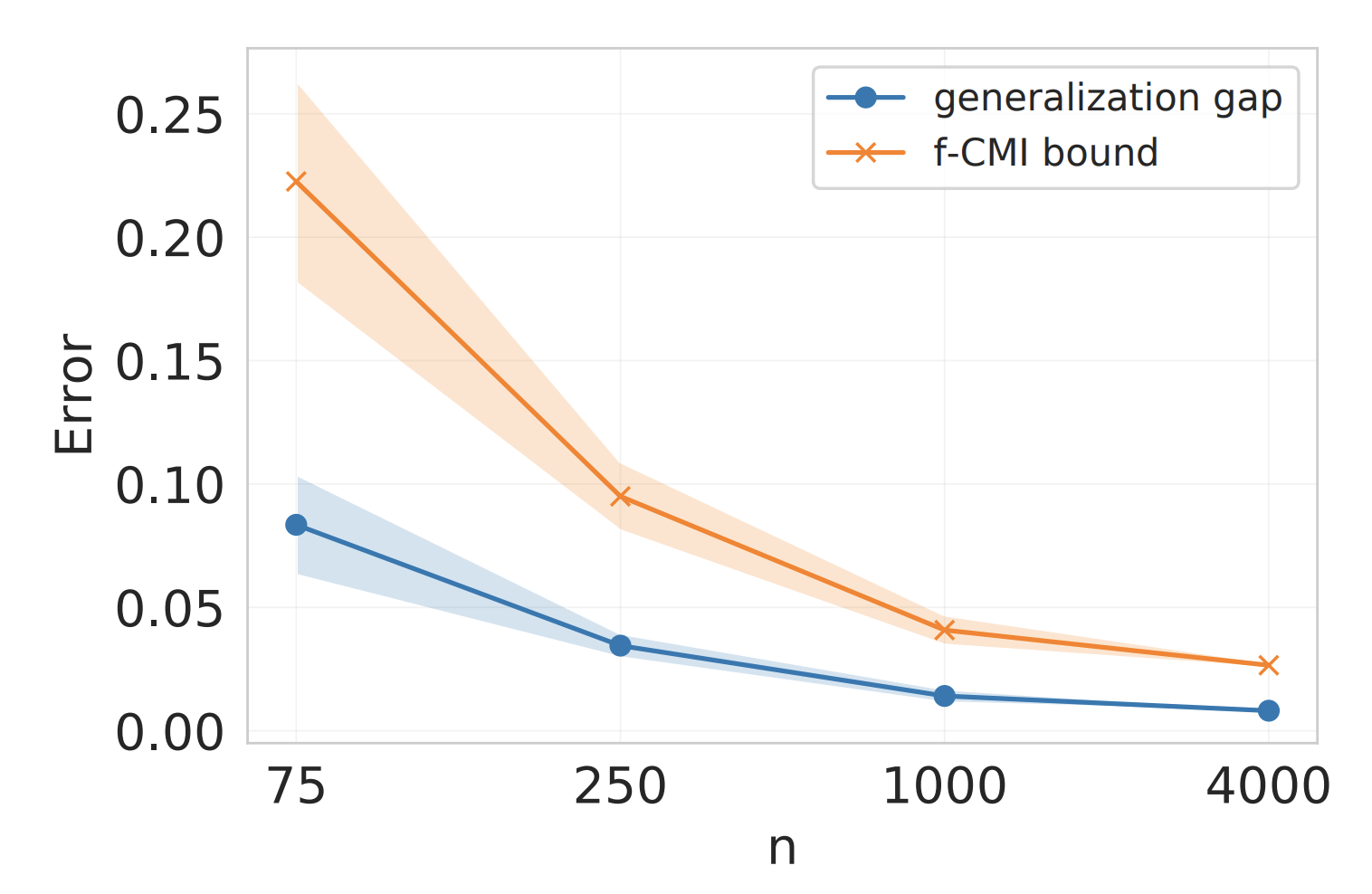
[Sept. 28, 2021] Our work “Information-theoretic generalization bounds for black-box learning algorithms” was accepted to NeurIPS 2021.
[May 17, 2021] Started a summer internship at AWS Custom Labels team. Will be working with Alessandro Achille and Avinash Ravichandran.
[Jan. 12, 2021] Our work "Estimating informativeness of samples with Smooth Unique Information" got accepted to ICLR 2021.
[Oct. 20, 2020] Received a free NeurIPS 2020 registration by making it to the list of the top 10% of high-scoring reviewers.
[June 3, 2020] Our work "Improving generalization by controlling label-noise information in neural network weights" got accepted to ICML 2020.
[May 18, 2020] Starting a summer internship at AWS Custom Labels team. Going to work with Alessandro Achille, Avinash Ravichandran, and Orchid Majumder!
[Jan. 3, 2020] I will be TA-ing CSCI 270: "introduction to algorithms and theory of computing" taught by Prof. Shahriar Shamsian this spring.
[Oct. 1, 2019] Our work titled "Reducing overfitting by minimizing label information in weights" got accepted to NeurIPS'19 information theory and machine learning workshop.
[Sept. 3, 2019] Our paper "Fast structure learning with modular regularization" got accepted to NeurIPS'19 as a spotlight presentation.
[Aug. 15, 2019] I will be the teaching assistant of CSCI 670: "advanced analysis of algorithms" taught by Prof. Shang-Hua Teng this fall.
Publications and preprints
Hrayr Harutyunyan, Ankit Singh Rawat, Aditya Krishna Menon, Seungyeon Kim, Sanjiv Kumar Supervision Complexity and its Role in Knowledge Distillation ICLR 2023, [paper, bibTeX]
Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student’s margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
Hrayr Harutyunyan, Greg Ver Steeg, Aram Galstyan Formal limitations of sample-wise information-theoretic generalization bounds IEEE Information Theory Workshop 2022 [arXiv, bibTeX]
Some of the tightest information-theoretic generalization bounds depend on the average information between the learned hypothesis and a single training example. However, these sample-wise bounds were derived only for expected generalization gap. We show that even for expected squared generalization gap no such sample-wise information-theoretic bounds exist. The same is true for PAC-Bayes and single-draw bounds. Remarkably, PAC-Bayes, single-draw and expected squared generalization gap bounds that depend on information in pairs of examples exist.
We propose an evaluation framework for domain generalization algorithms that allows decomposition of the test error into components capturing distinct aspects of generalization. We show that the largest contributor to the generalization error varies across methods, datasets, regularization strengths and even training lengths. We observe two problems associated with the strategy of learning domain-invariant representations. On Colored MNIST, most domain generalization algorithms fail because they reach domain-invariance only on the training domains. On Camelyon-17, domain-invariance degrades the quality of representations on unseen domains. We hypothesize that focusing instead on tuning the classifier on top of a rich representation can be a promising direction.
We derive information-theoretic generalization bounds for supervised learning algorithms based on the information contained in predictions rather than in the output of the training algorithm. These bounds improve over the existing information-theoretic bounds, are applicable to a wider range of algorithms, and solve two key challenges: (a) they give meaningful results for deterministic algorithms and (b) they are significantly easier to estimate. We show experimentally that the proposed bounds closely follow the generalization gap in practical scenarios for deep learning.
Hrayr Harutyunyan, Alessandro Achille, Giovanni Paolini, Orchid Majumder, Avinash Ravichandran, Rahul Bhotika, Stefano Soatto Estimating informativeness of samples with smooth unique information ICLR 2021 [arXiv, code, bibTeX]
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples.
Hrayr Harutyunyan, Kyle Reing, Greg Ver Steeg, Aram Galstyan Improving generalization by controlling label-noise information in neural network weights ICML 2020 [arXiv, code, bibTeX]
In the presence of noisy or incorrect labels, neural networks have the undesirable tendency to memorize information about the noise. We show that one can prevent memorization and improve generalization by controlling the Shannon mutual information between weights and the vector of all training labels given inputs, I(w ; y ∣ x). To minimize this information, we propose training algorithms that employ an auxiliary network that predicts gradients in the final layers of a classifier without accessing labels. Our approach yields drastic improvements over standard training algorithms (like cross-entropy loss), and outperform competitive approaches designed for learning with noisy labels.
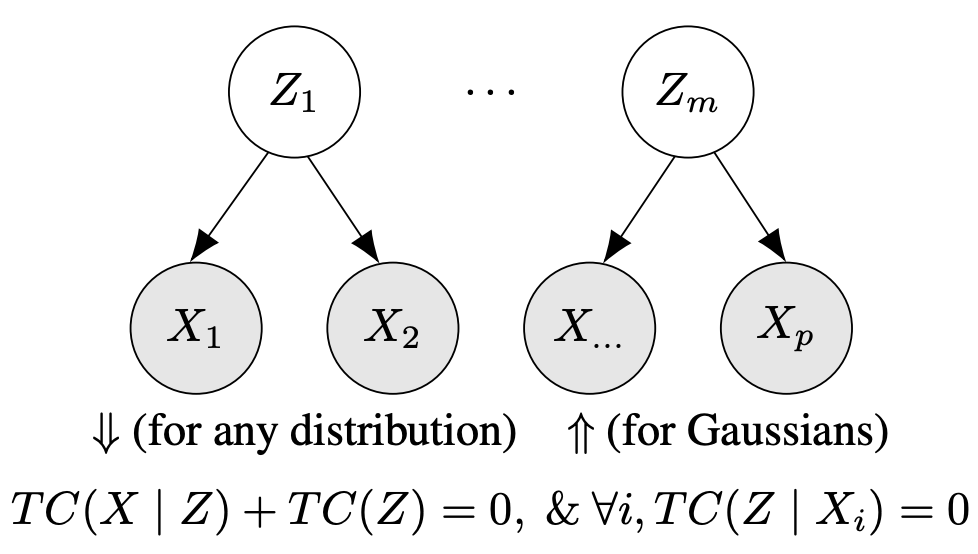
Greg Ver Steeg, Hrayr Harutyunyan, Daniel Moyer, Aram Galstyan Fast structure learning with modular regularization NeurIPS'19 [arXiv, code, bibTeX]
We introduce a method, called linear CorEx, for learning latent factors such that the joint probability distribution becomes close to being a modular latent factor model (shown in the picture). The method has linear complexity w.r.t. the number of observed variables and works well in high-dimensional undersampled regimes. Furthermore, when the data comes from an approximately modular Gaussian latent factor model, linear CorEx exhibits blessing of dimensionality!
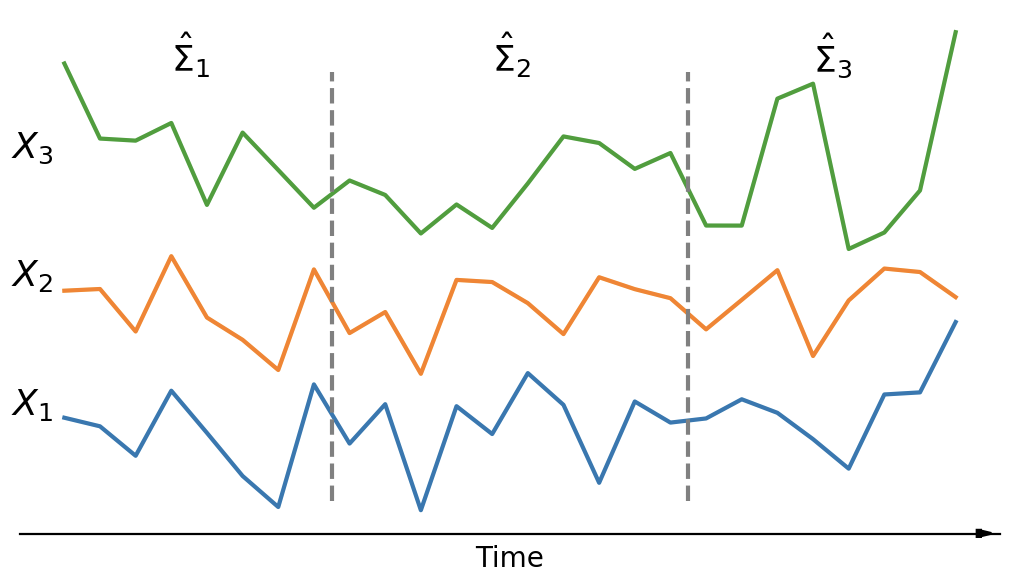
Hrayr Harutyunyan, Daniel Moyer, Hrant Khachatrian, Greg Ver Steeg, Aram Galstyan Efficient Covariance Estimation from Temporal Data arXiv preprint [arXiv, code, bibTeX]
In this work we extend linear CorEx to work with temporal data. The main method -- T-CorEx -- takes multivariate time series, divided into time periods and models the data of each time period with an instance of linear CorEx, such that the models vary smoothly over time. The method can be used for estimating covariance matrix of observed variables at each time period, clustering of time series, change point detection, and extracting useful information. All these analyses can be done in less than an hour even when the data is truly high-dimensional (like an fMRI instance with 10^5 variables and 20 time periods).
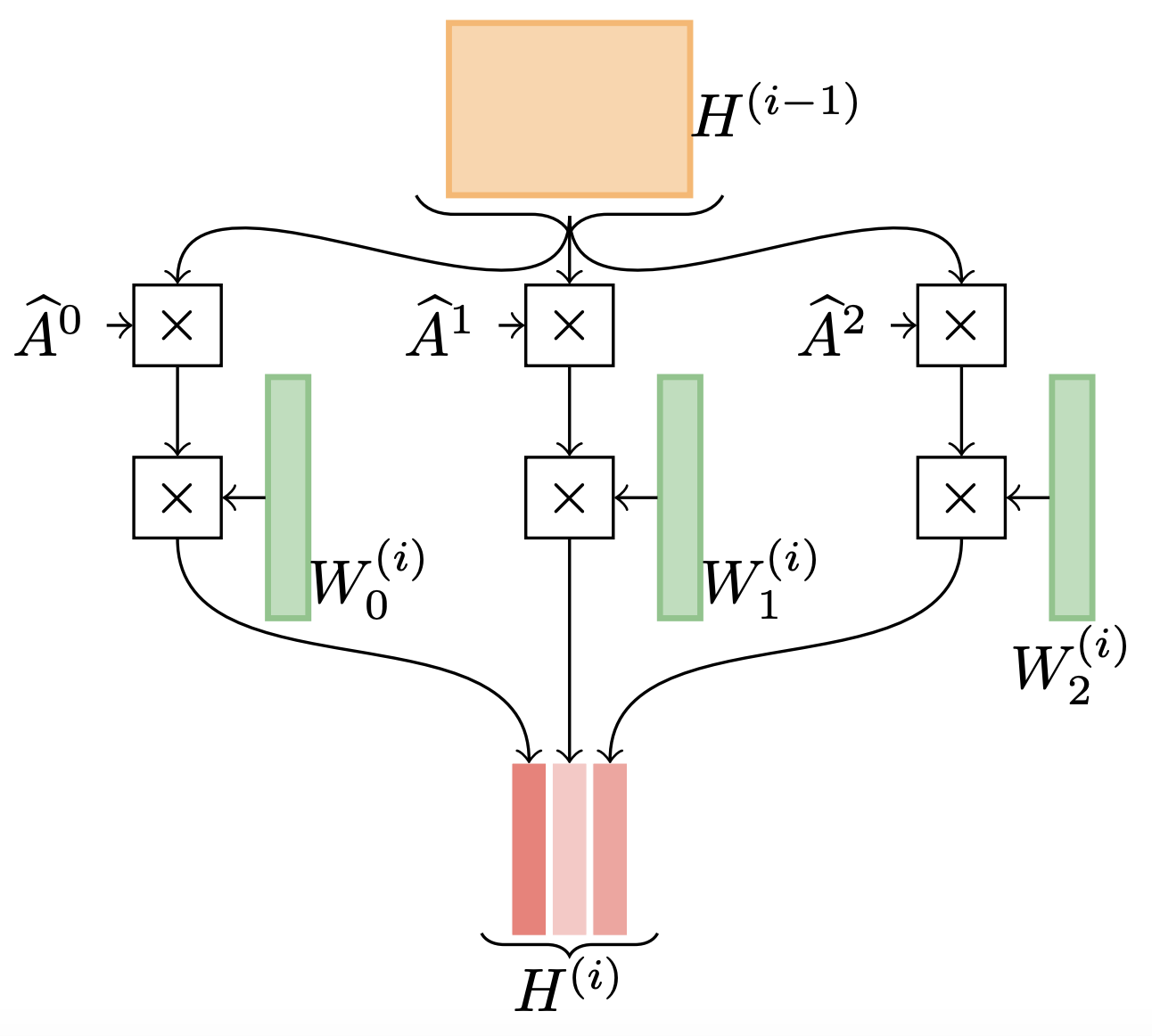
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Hrayr Harutyunyan, Nazanin Alipourfard, Kristina Lerman, Greg Ver Steeg, Aram Galstyan Mixhop: Higher-order graph convolution architectures via sparsified neighborhood mixing ICML'19 [arXiv, code, bibTeX]
This paper proposes a new graph convolutional network (GCN), called MixHop, that in contrast to the vanilla GCN is able to learn a general class of neighborhood mixing relationships. MixHop requires no additional memory or computational complexity. Additionally, the paper proposes sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets.
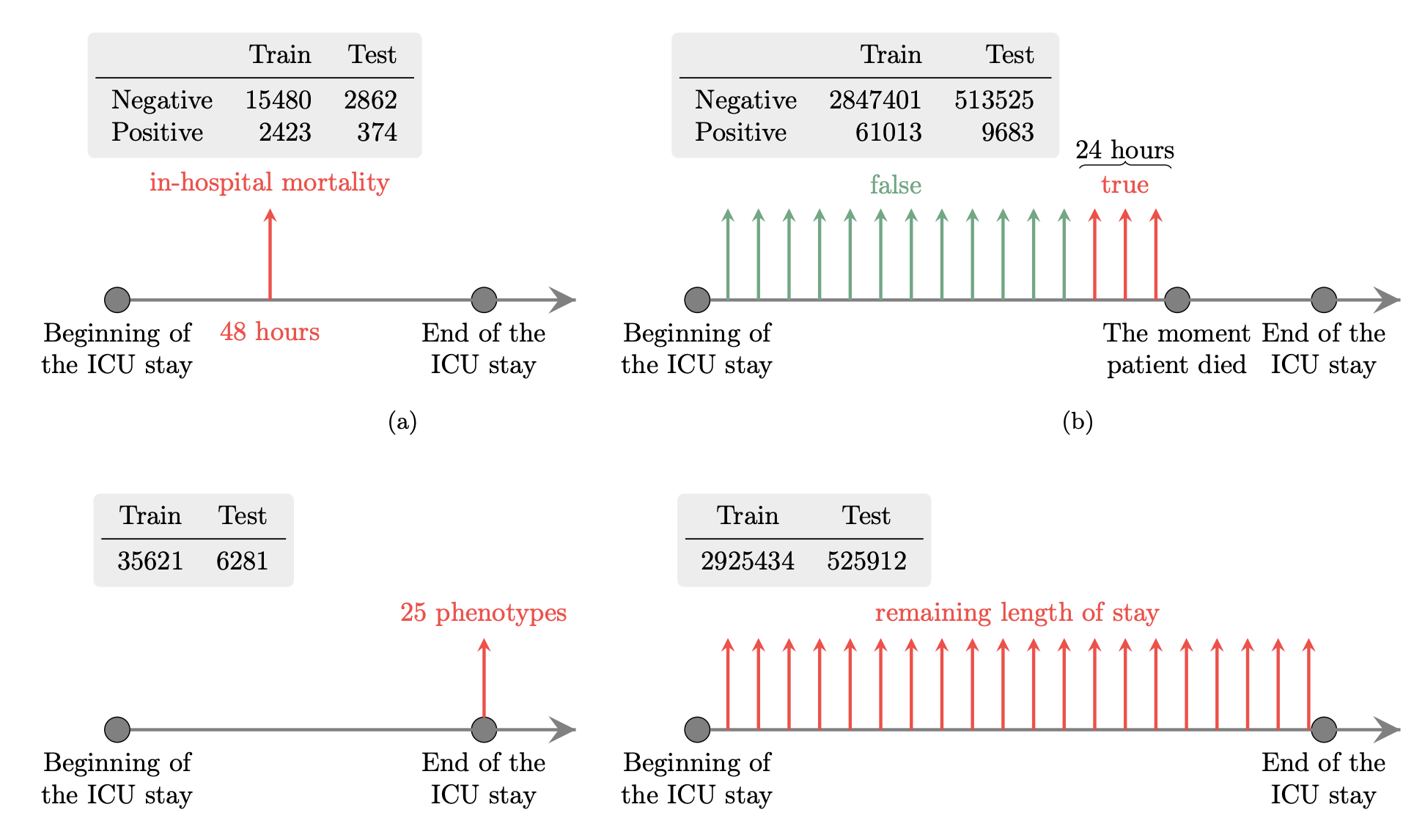
Hrayr Harutyunyan, Hrant Khachatrian, David Kale, Greg Ver Steeg, Aram Galstyan Multitask learning and benchmarking with clinical time series data Nature, Scientific data 6 (1), 96 [arXiv, code, bibTeX]
The progress in machine learning for healthcare research has been difficult to measure because of the absence of publicly available benchmark data sets. To address this problem, we propose four clinical prediction benchmarks using data derived from the publicly available MIMIC-III database. These tasks cover a range of clinical problems including modeling risk of mortality, forecasting length of stay, detecting physiologic decline, and phenotype classification. We propose strong linear and neural baselines for all four tasks and evaluate the effect of deep supervision, multitask training and data-specific architectural modifications on the performance of neural models.
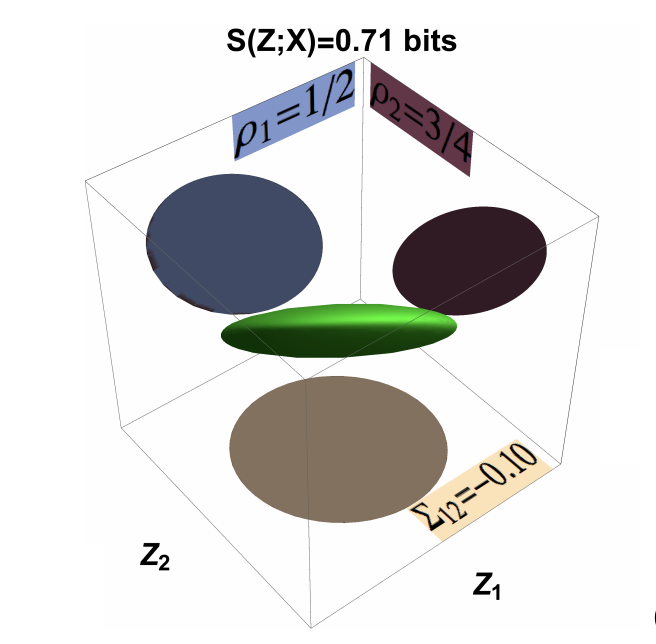
Greg Ver Steeg, Rob Brekelmans, Hrayr Harutyunyan, Aram Galstyan Disentangled representations via synergy minimization Allerton'17 [arXiv, bibTeX]
If the factors comprising a representation allow us to make accurate predictions about our system, but obscuring any subset of the factors destroys our ability to make predictions, we say that the representation exhibits informational synergy. We argue that synergy is an undesirable feature in learned representations and that explicitly minimizing synergy can help disentangle the true factors of variation underlying data. We explore different ways of quantifying synergy, deriving new closed-form expressions in some cases, and then show how to modify learning to produce representations that are minimally synergistic. We introduce a benchmark task to disentangle separate characters from images of words. We demonstrate that Minimally Synergistic (MinSyn) representations correctly disentangle characters while methods relying on statistical independence fail.